Quickly changing modern world conditions and rising competition requires businesses to make correct decisions faster in order to be successful. This, in turn, requires better data analysis tools to always be able to see a big picture.
Many businesses choose cloud data warehouse services, like Amazon Redshift, Google BigQuery, etc. to analyze their data, as they offer high scalability and on-demand computing power and are supported by a large number of various data analysis tools. This allows companies to quickly and comprehensively analyze data and get informative reports even for largest data volumes in a reasonable time.
However, corporate data are often spread between different systems and applications, and before analyzing them, one must get them to a data warehouse first. Besides, getting data to a warehouse is just a part of a problem: to convert data to correct decisions, you need to use as fresh data as possible, and thus, you must keep data in the data warehouse up-to-date.
Let’s consider a more specific case when there is a need to analyze company data from a Jira system, and Google BigQuery is selected as a data warehouse for analysis. There can be different ways to solve this scenario. One can either develop his own solution or check the market for existing tools.
Creating a custom solution based on Jira REST API
When creating a custom ETL solution, one should consider many aspects - from the choice of a platform and tools to use to specifics of integrated data sources. Additionally, the solution must be automated, to keep data in sync with as less manual work as possible.
The first thing you should start with in creating a custom integration is to study the Jira REST API. The detailed documentation on it can be found here: https://docs.atlassian.com/jira/REST/cloud/
These API allows extracting Jira data, and return these data in the JSON format. Thus, the next step will be to define BigQuery schema to store Jira data and to convert the extracted data to a format, suitable for import to BigQuery.
After this, you need to load this data into BigQuery. BigQuery documentation offers several ways for loading data.
And the final step will be automating this process in order to keep the data in sync without the need of user interaction.
Developing a custom solution may be a complex task. It requires certain development knowledge and specific tools. Besides, the developer must study API of the integrated sources, and keep the solution up-to date in case when this API changes.
Thus, finding a proven third-party tool, whose developers already solved this task, is often a better and more effective solution.
Using Skyvia to load Jira data to BigQuery in minutes
For our scenario we have selected Skyvia to perform data replication. Skyvia is a cloud data platform for various data-oriented tasks, such as data integration, backup, and management. It supports all major SaaS applications, databases and flat files. In particular, Skyvia is well-suited for loading data between various sources, including Jira and BigQuery.
Being a partner of both Jira and Google BigQuery, Skyvia offers tools for both quick and easy data replication from Jira to BigQuery with little configuration (ELT), and for advanced data import with powerful transformations (ETL). Data loading can be easily automated with Skyvia.
Configuring Jira data replication to BigQuery is intuitive and takes just several minutes. Skyvia can load your existing Jira data to BigQuery as well as keep this data up-to-date with Jira automatically after the initial load.
Configuring Replication in Skyvia
To use Skyvia replication, first you need to create the account (or you can simply sign in with Google or Salesforce) on the website.
In the created account, you can immediately start configuring our replication package.
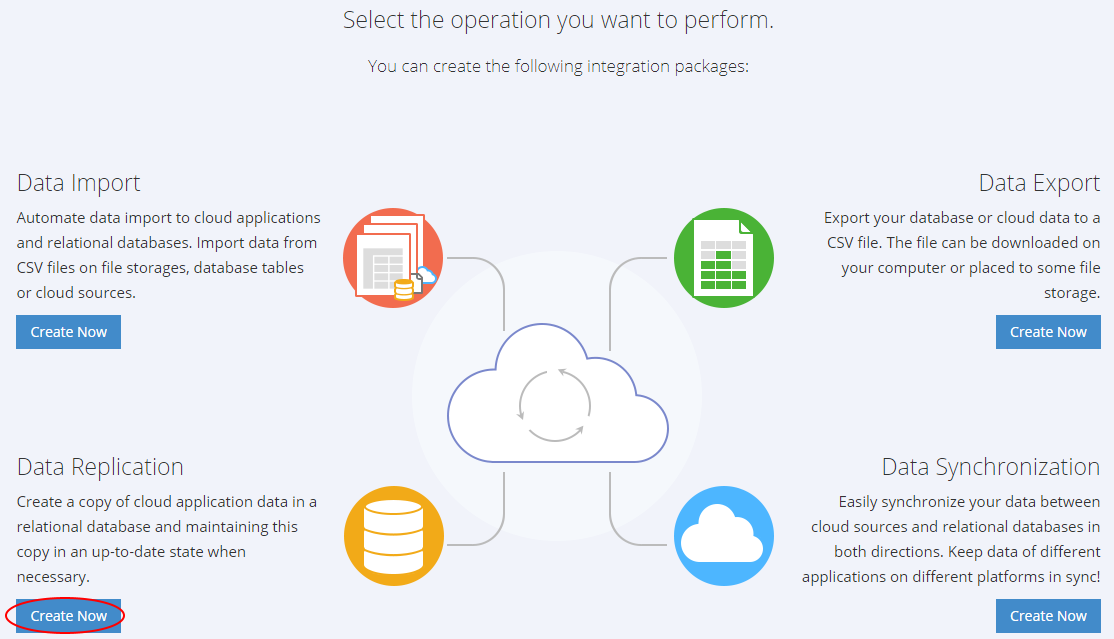
Actually, you only need to perform the following three simple steps:
1. First, you need to select the data source kind and create the necessary connections to the Jira account for Source and to BigQuery for Target.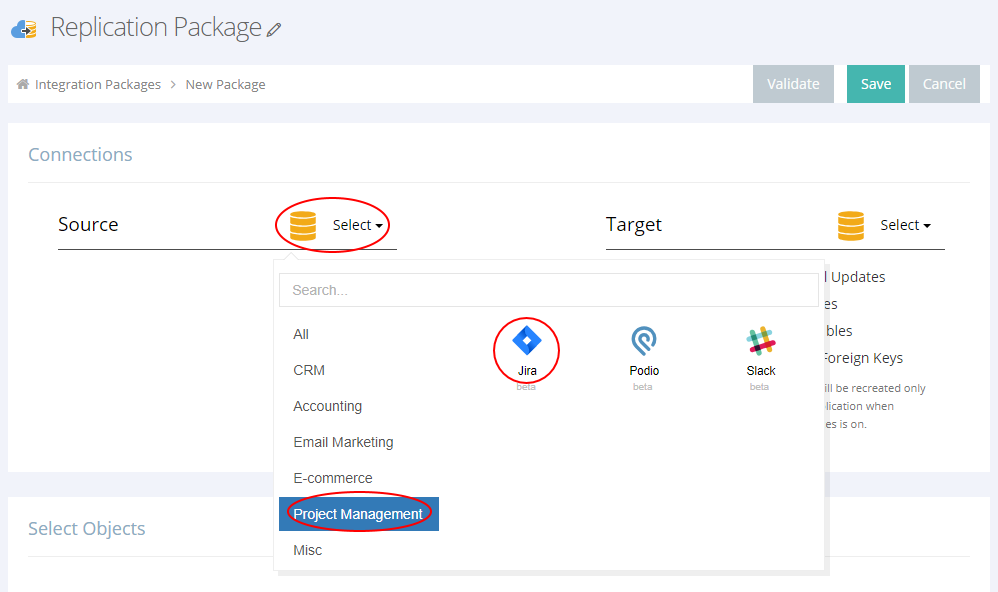
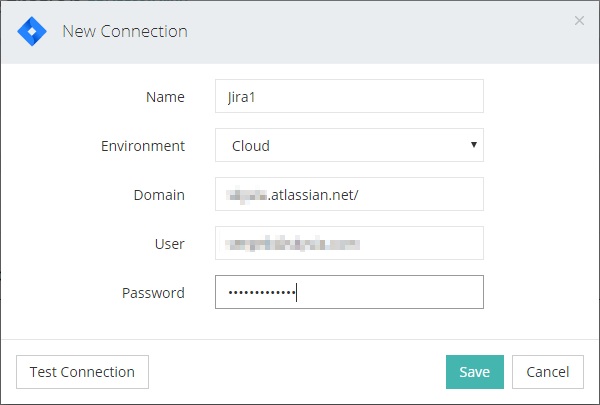
For a Jira connection, you need to specify the domain to connect to and Jira username and password.
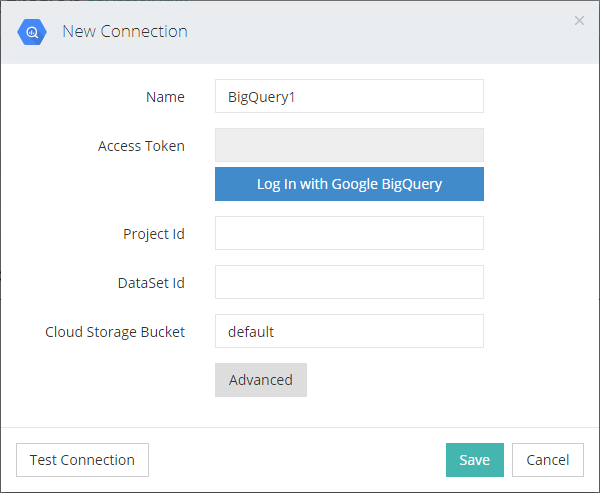
For a BigQuery connection, you need to log in with Google BigQuery and allow access for Skyvia. Then you need to provide the ID's of a project and a dataset to connect to.
2. After this you need simply to select, which data you want to replicate from Jira.
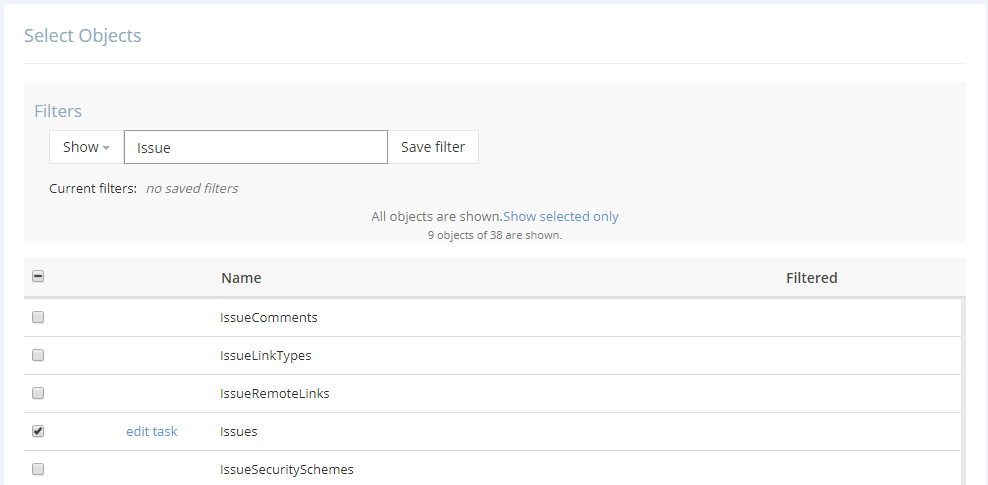
3. Then the package can be scheduled for automatic execution so that you always have up-to-date data in BigQuery, and that’s all.
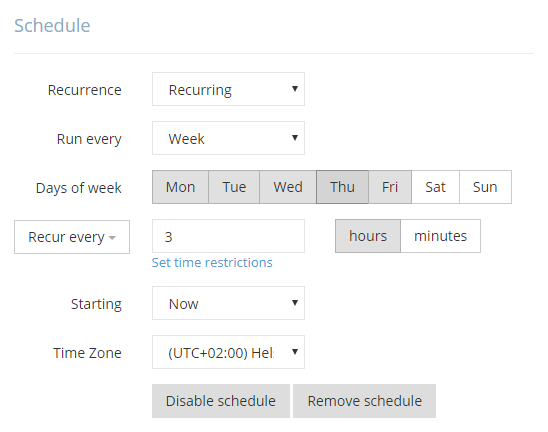
After you save the package, it will run automatically on the schedule, and keep BigQuery data up-to-date with Jira. The data will be always readily available for your data analysis or reporting tools, and its maintenance won't require any more of your attention.
This is a guest blog post by Sergei Kharchenko, Product Marketing Manager at Skyvia. You can learn more about Skyvia and its features with the following data integration video tutorial and backup video tutorial.



