No software and no technical infrastructure is perfect: It's not a question of "whether" there will be disruptions or outages but "when" and "for how long." And software system failure is always costly. If it's a public system, customers and users are no longer able to use the service; while an internal system failure leads to a loss of productivity and work left undone.
This is why, in the event of a failure, any enterprise would strive to solve any problem as quickly as possible. However, this is rarely subject to any particular structure. Below is a perfect example of how this has probably played out in some form or another in many companies until now.
An incident and the general panic that ensues
If something is broken, it doesn't take long until customers start to contact the company – the support team, the product owners in the teams, the amount managers. The classic scenario is that panic then breaks out.
The account manager gets on the phone or on starts a chat and rounds up as many people as they possibly can. The fact that some of those alerted quickly see that their colleagues are already working on the problem is of secondary importance for now. The account executive consciously adopts the principle that it's better to get too many people involved than too few.
They pelt annoyed administrators with questions. After all, the account manager knows little more than the customer about how long things have been down for, what is being done to fix it, and how long it will take. The snippets of information they are given are passed straight on to the customer. But these details are not particularly well-founded or transparent.
And so the account manager continues to bombard the technical team with their questions, while the team is actually trying to work on fixing the problem. In one phone call, someone from the IT team snaps back: "I can only do one thing at a time – talk on the phone or work on the problem. So please tell me, what is more important right now?"
All in all, it's a stressful time for everyone – for the customer, whose software is down; for the account manager, who is stuck in limbo and desperate for information; for the IT team, who have countless tasks to get done while being constantly distracted by panicked enquiries, which have been triggered by the blanket alarm set off for nothing.
In the end, they find a solution, and everything goes back to normal, but no one is really satisfied. Will anyone actually do anything to prevent a disturbance like this in the future?
Atlassian Opsgenie can help to take much of the sting out of such an incident.
Automated alarms and escalation
In Opsgenie, on-call schedules ensure that the right people are informed in case of a disturbance – and this is automated within the system. For example, when Opsgenie detects a problem via its integration with a connected monitoring system (there are more than 200 integrations available for third-party applications), it automatically forwards it on to the right contact person without the company having to do anything.
The communication channels that should be used to alarm the team members – email, text message, or telephone – can be predefined. But what if someone is unavailable via the preset channel? In such a case, Opsgenie will escalate the case and try a different channel and/or another team member: Flexible escalation levels can be predefined in the software settings. Opsgenie will continue to escalate until someone begins to work on the problem.
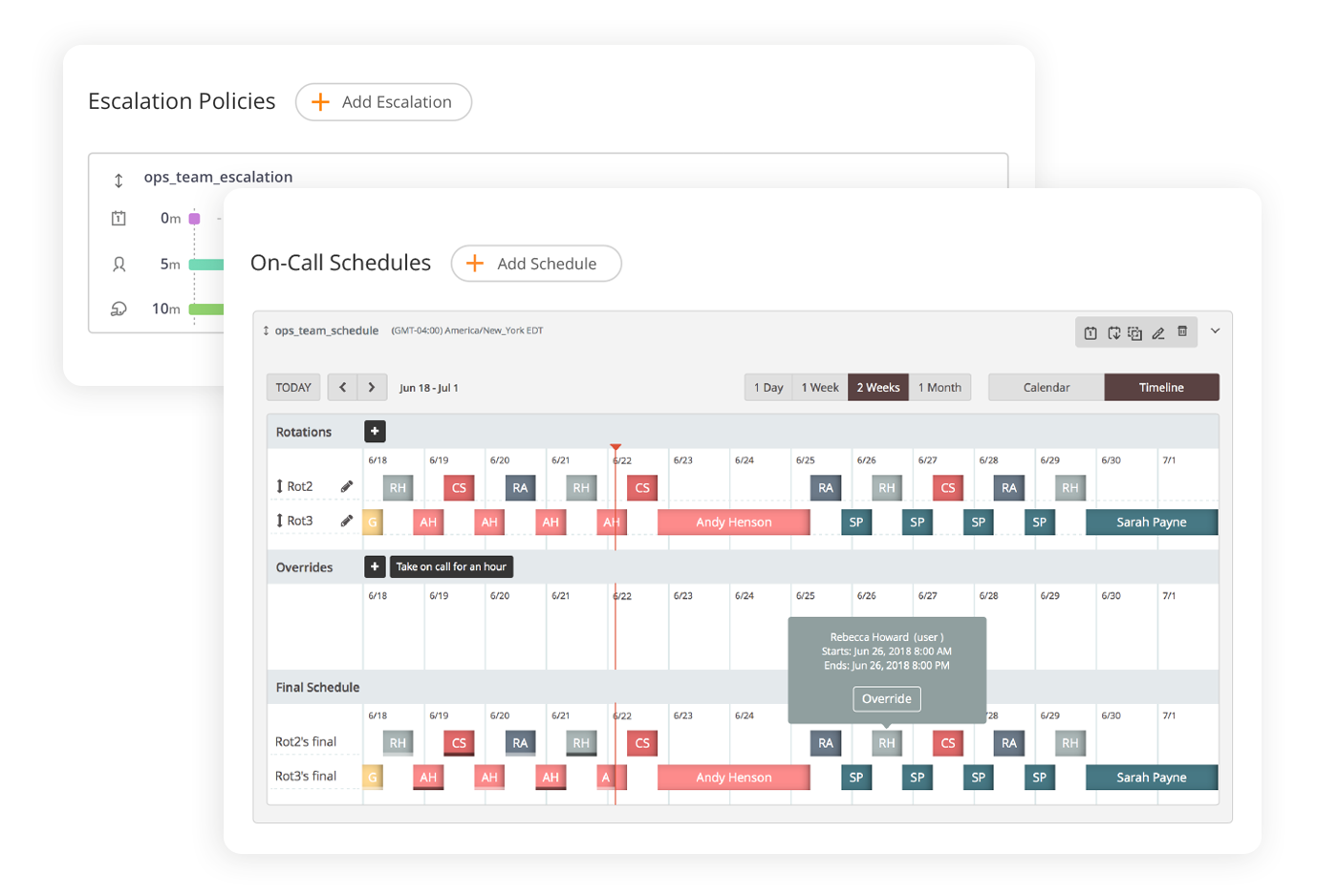
Flexible on-call management in Opsgenie
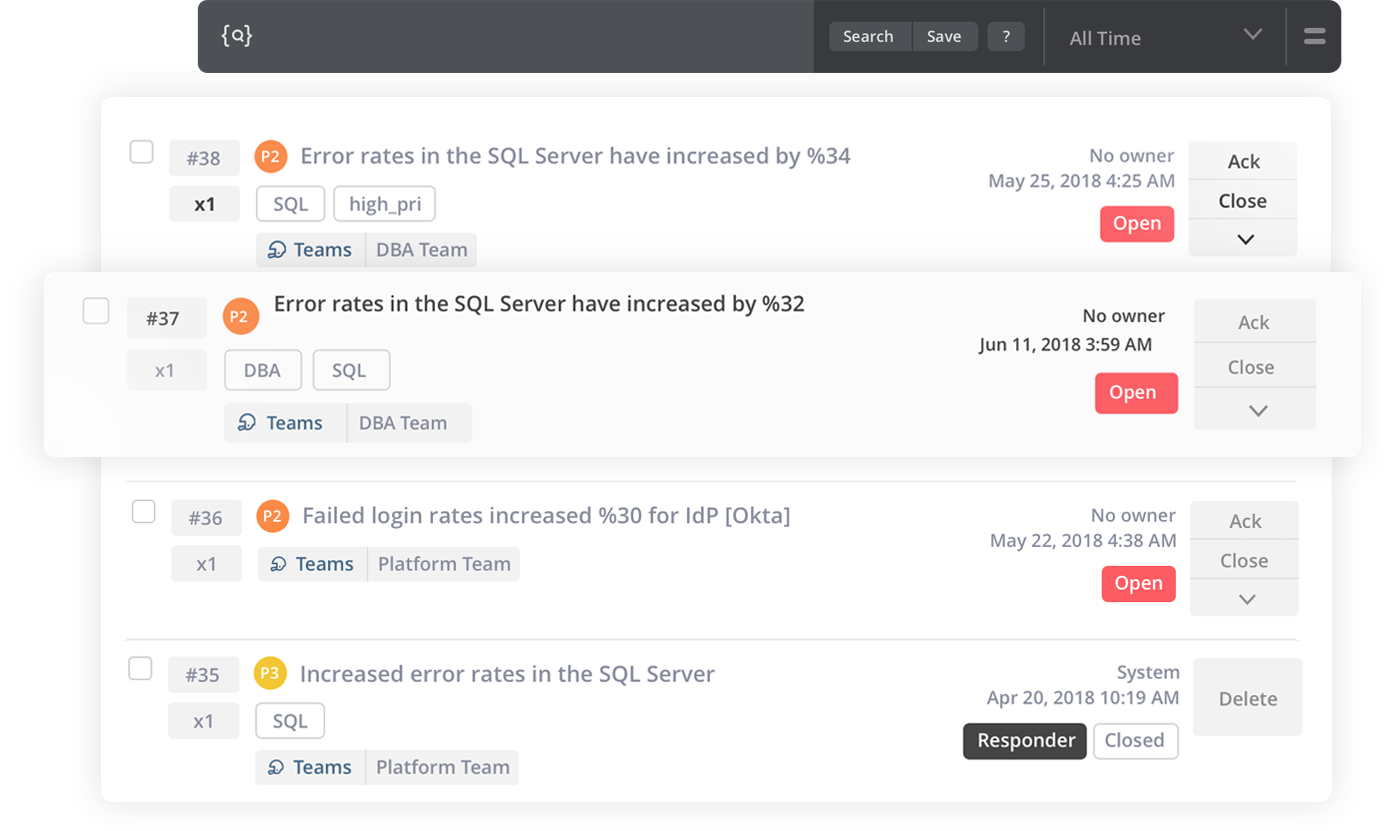
If a problem is detected, Opsgenie autonomously starts the alerting process
Transparency throughout the entire process
Opsgenie ensures transparency around the escalation of the problem as well as the subsequent handling of the incident – and this also applies to people such as the account manager mentioned in the example above. There are free stakeholder licenses available for Opsgenie, which allow people outside of the technical team directly involved access to the current system and status information.
Who is currently working on the problem? Which measures are being taken? A stakeholder has clarity on such questions at all times, and they can be sure that the right people are working on the problem. As such, it isn't necessary to alarm other team members themselves. It is also no longer necessary to bombard highly focused admins to get any morsels of information they can. The account manager can follow everything in the system live and up-to-date and send details on the status of the problem to customers if necessary.
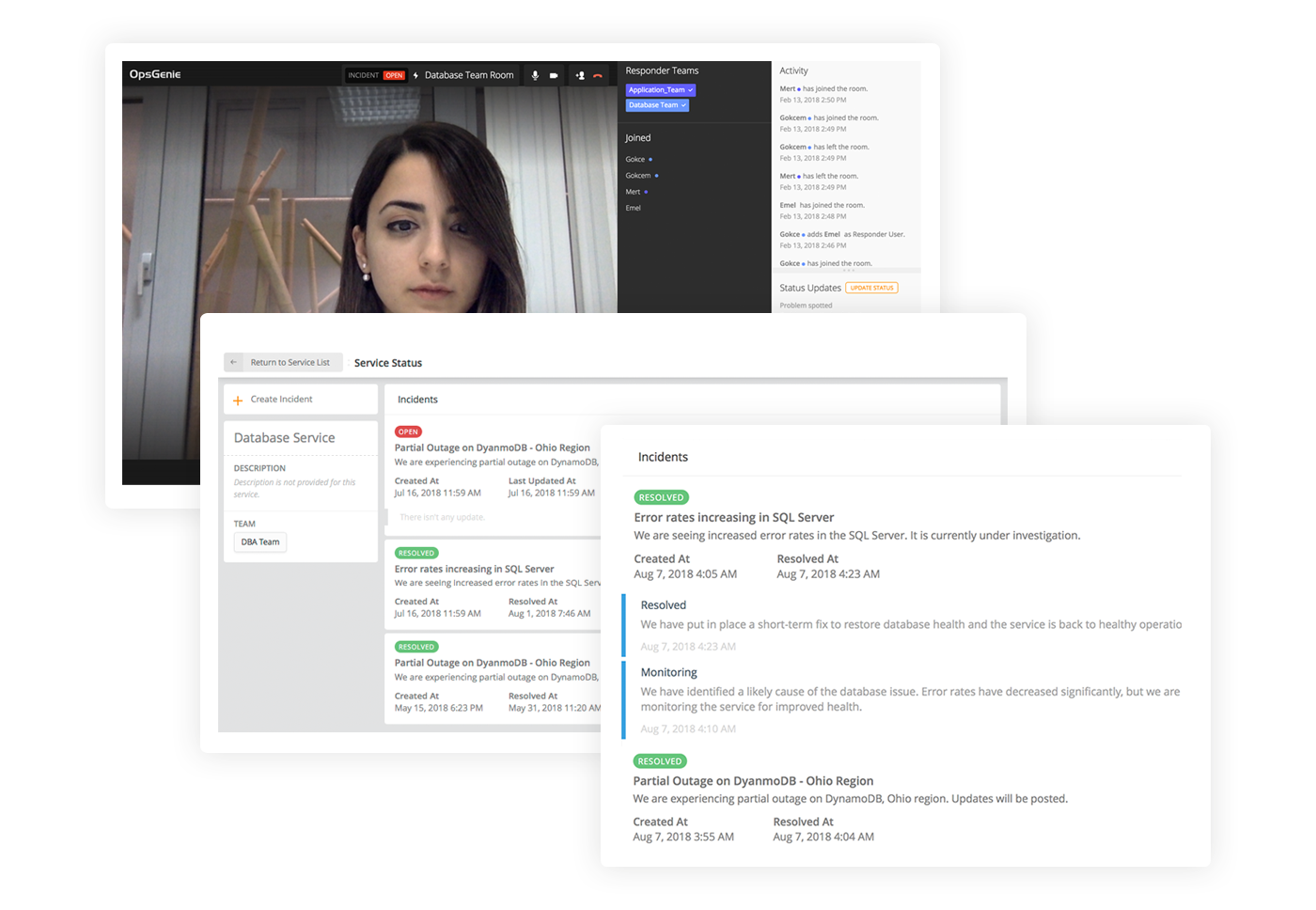
Opsgenie offers transparency throughout the entire incident management process
Dataset for post-incident analysis
To prevent the admin teams from succumbing to the (understandable) temptation to simply go back to daily business and focus on their other tasks once the problem has been solved, Opsgenie offers a so-called post-incident analysis feature. This refers to the structured retrospective analysis of an incident to avoid similar disturbances in the future. Learning from challenges faced is just as important as solving them.
The system produces detailed reports, which can provide a dataset for such analysis. In combination with Confluence and corresponding area and page templates, the system can follow up on incidents systematically. Ideally, the team then goes on to log the tasks that might result from such analysis in a linked Jira system. Atlassian is currently working hard on Jira Ops, which will provide a number of different features and automatizations for this use case too.
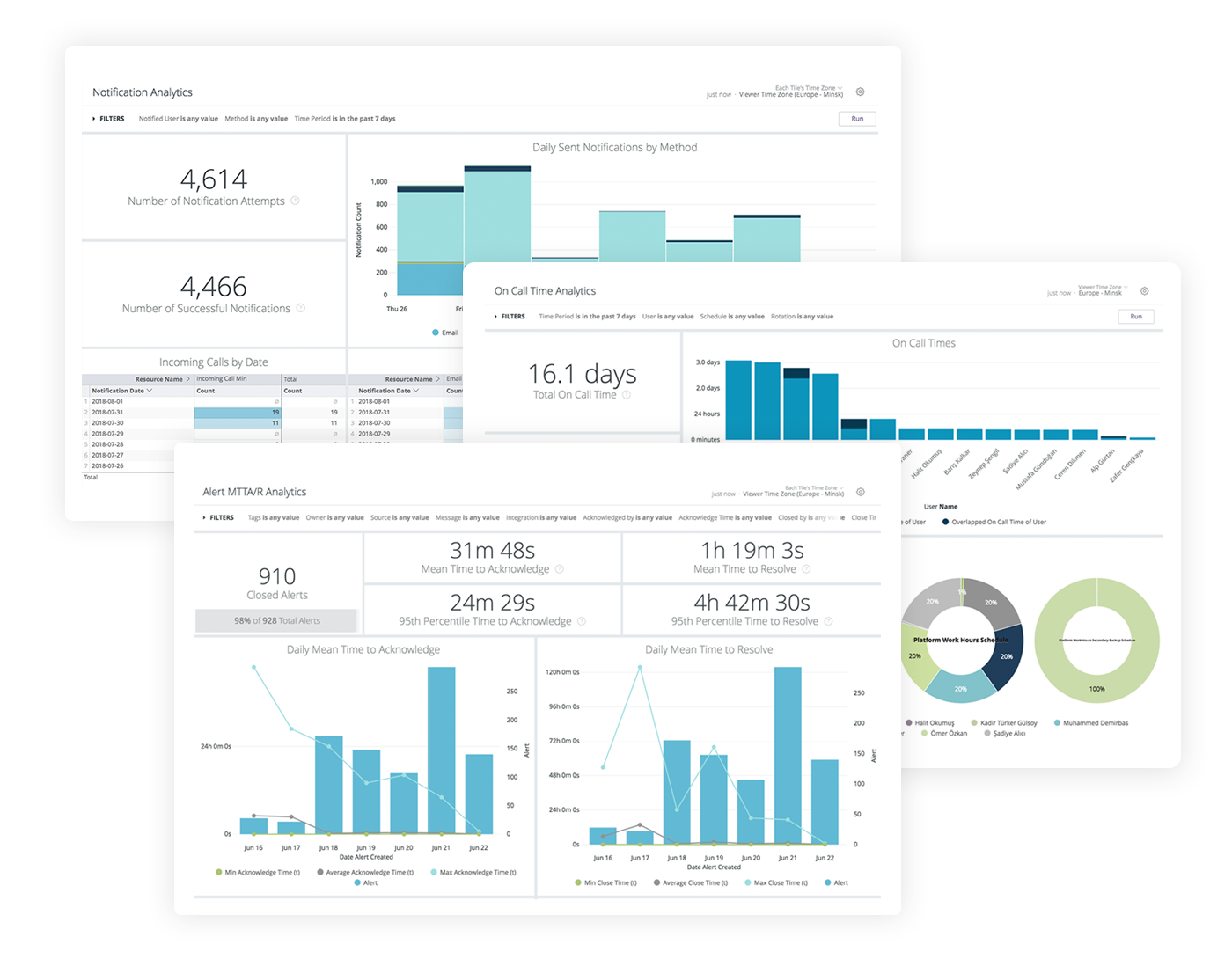
An extensive dataset on each incident helps with post-incident analyses
Atlassian Opsgenie gives companies a tool to create a systematic incident management procedure and channel it into a flexible, automated, and clear process. It gives the admin teams involved a great deal of flexibility, helps to guarantee that the right team members can get to work on solving the problem as quickly as possible, and also ensures transparency and security. Furthermore, Opsgenie provides the data needed to draw the right conclusions from such an incident.
We are your partner for Atlassian Opsgenie
Do you want to know more about Atlassian Opsgenie? Would you like to talk about how to establish a structured alerting process for specific applications in your organization? Then get in touch! We are an Atlassian Platinum Solution Partner and can support you in all aspects of systematic incident management in your organization.
Lesen Sie diese Seite auf Deutsch
Further information
Opsgenie – Modern incident management
Atlassian Summit 2018: The most important news from the product keynote
Purchasing Atlassian licenses via //SEIBERT/ MEDIA - your advantages



