We learn the most from our failures
The best stories are the ones where things go completely belly-up. After all, they're the ones that teach us the most. So we don't want to boast about all of the hundreds of systems that we have equipped with security patches and where automatizations have picked up on errors before the customer even realized that something was wrong. Braggers would tell tales of customers being full of praise and how more and more of them are using such operation packages for their systems.
No, sometimes there has to be a bit of crash and bang! Raging tempers! Cursing admins, steam coming out of ears, frustrated customers! We've seen it all. Here are a few examples:
One of our customers had two employees who had taken on the task of managing the Linchpin server operation for over 10,000 users. Such system experts are quite sought after on the market. And before they knew it, there was no one left who knew how to operate the servers, let alone carry out any kind of maintenance on them. Then all it takes is a full hard drive, and the managing director is faced with thousands of angry users who want answers. "At times like this, I can understand why everyone loves the cloud," they said to us. "That way, someone else is always responsible for sorting out these kinds of details."
One would like to think that when a system goes down like that, the worst-case scenario has already taken place. After all, the users can't use the system. But of course, we have tried to help customers to reconstruct data and carefully extract individual Confluence pages (including attachments) in the past.
In one case that I found particularly unpleasant, the system was down, but we still couldn't help them because the company's RSA token had run out (and they knew it, too). But the outsourced IT department said that they couldn't take care of the new token for another eight days, so the system had to stay down for all that time!
After years of preaching the advantages of collaboration software, setting an example, and attracting attention to it with PR stunts, one week of downtime proved to be much faster and more sustained in its effect – unfortunately, it wasn't the kind we would've hoped for. No one came out of this one with a smile on their face.
Emergency support exclusive to operation package holders
I have read a lot about storytelling. But we don't want to follow such stories any further. When something like this happens, you don't just lose one sailor, but all of a sudden, Word, PowerPoint, Excel, and meetings come back to life again – and yes, the much-detested email makes a comeback too. Does anybody really want this to happen?! No!
This is why we had to use force. The expression might sound a little crude, but it stands for something serious: We will only be helping in emergencies if we have or get an operation agreement.
One of our company values is: " We love to be in charge!" But that can only work if we can guarantee a few fundamental things.
In the past, we have often made exceptions here and there. "Yeah, sure, we can do WebEx, too," we thought. But then the customer closed their ranks at 6pm, and we had to wait until 8am the next morning to start working again. "Really?! You're going home now?" – "Of course. It's home time. It's not that important. It can wait." – "Umm, but we need to get the system up and running again. Hundreds of your teams need to use it again tomorrow. It'll cost you thousands of euros! Maybe more!" – "Yeah, sure, I'll speak to you tomorrow."
I'm not trying to give our customers a telling-off. I understand their employees too. And I know that it can sometimes be frustrating in large companies. But we won't be going along with it any longer. The best way to go about it is to create a professional foundation from the very start, which then forms the basis going forward. No, that's not clear enough: We will go along with it if the fundamental requirements for professional operation have been met.
Two essential requirements for effective support
I don't want to beat around the bush. It comes down to this:
- With an operation package, our experts have reliable, unrestricted access to your systems. Or you might even choose to have us host them. This allows us to monitor them professionally. This is the only way that our automatizations, early-warning systems, and the other mechanisms that we need to lend some structure to our working days and prevent constant emergencies, can do their job correctly.
- And this: "The customer isn't given root access to the system but a Linux user with restricted permissions. A documented route to gain full root permissions is available for emergencies."
There are, of course, many more advantages, and if you like, you can find more details on the info page about our operation packages for Atlassian products. But those are probably the two most important aspects.
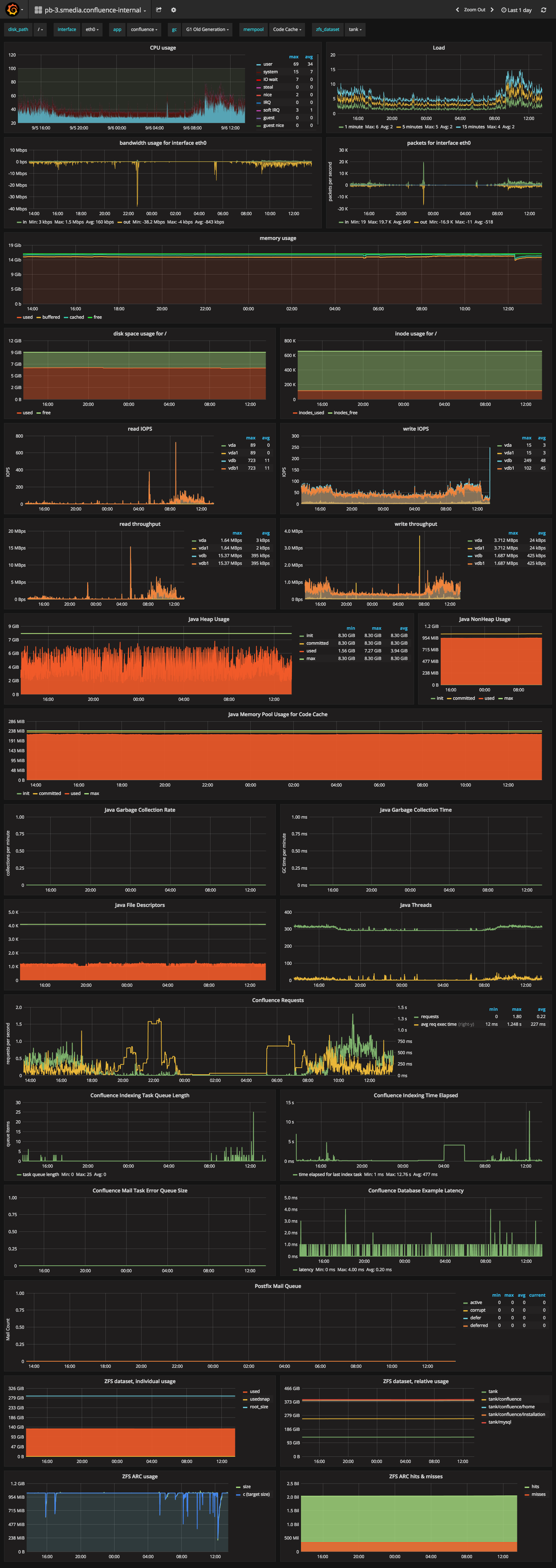
Systematic monitoring is part of our Atlassian operating systems: Some system metrics are even monitored every ten seconds. This ensures that chronological documentation showing the development of the respective values is available for use to solve the problem. This is an example of an overview of the data collected.
And yes, I am deadly serious. No exceptions any longer. In serious cases, we will do as an automotive break-down service would... If you don't have a service agreement yet, you can sign one there and then. However, we would need to have enough capacity to complete it. And in many companies, it isn't all that easy to finalize an emergency agreement so quickly. Agreements can take longer than a down system can wait. So we would ask you to take the necessary steps before it comes to this.
We want to take on responsibility and help you effectively. Nowadays, automatizations, fast problem-solving, and routined procedures are all a part of it. In the future, we will guarantee these to all customers on a uniformly high level. We will leave the experiments and stories of smoking or even blazing server system landscapes to someone else.
This article is the start of an extensive information campaign for our customers. I am sure and have already seen that this is the right way to do things. But we learn something new every day. If you have questions or concerns, you are welcome to get in touch at any time. I look forward to hearing from you!
Further information
Operation Package For Your Atlassian Applications
Transparency and preventing nasty surprises: Operation packages for Atlassian applications with monitoring
The frustrated son – a story of data loss and backup concepts for Atlassian products
Linchpin Service Package: Full Technical Support for Your Linchpin Instance



